CONVINCE: Collaborative Cross-Camera Video Analytics at the Edge
Overview
Driven by drastic fall in camera cost and the recent advances in computer vision-based video inference, organizations are deploying cameras in dense for different applications rang-ing from monitoring industrial or agricultural sites to retail planning. As an example, Amazon Go features an array of 100 cameras per store to track the items and the shoppers. Processing video feeds from such large deployments, however, requires a considerable investment in compute hardware or cloud resources. Due to the high demand for computation and storage resources, Deep Neural Networks (DNNs), the core mechanisms in video analytics, are often deployed in the cloud. Therefore, nowadays, video analytics is typically done using a cloud-centered approach where data is passed to a central processor with high computational power. However, this approach introduces several key issues. In particular, executing DNNs inference in the cloud, especially for real-time video analysis, often results in high bandwidth consumption, higher latency, reliability issues, and privacy concerns. Therefore, the high computation and storage requirements of DNNs disrupt their usefulness for local video processing applications in low-cost devices. Hence, it is infeasible to deploy current DNNs into many devices with low-cost, low-power processors. Worst yet, today video feeds are independently analyzed. Meaning, each camera sends its feed to the cloud individually regardless of considering to share possible valuable information with neighbor cameras and to utilize spatio-temporal redundancies between the feeds. As a result, the required computation to process the videos can grow significantly.
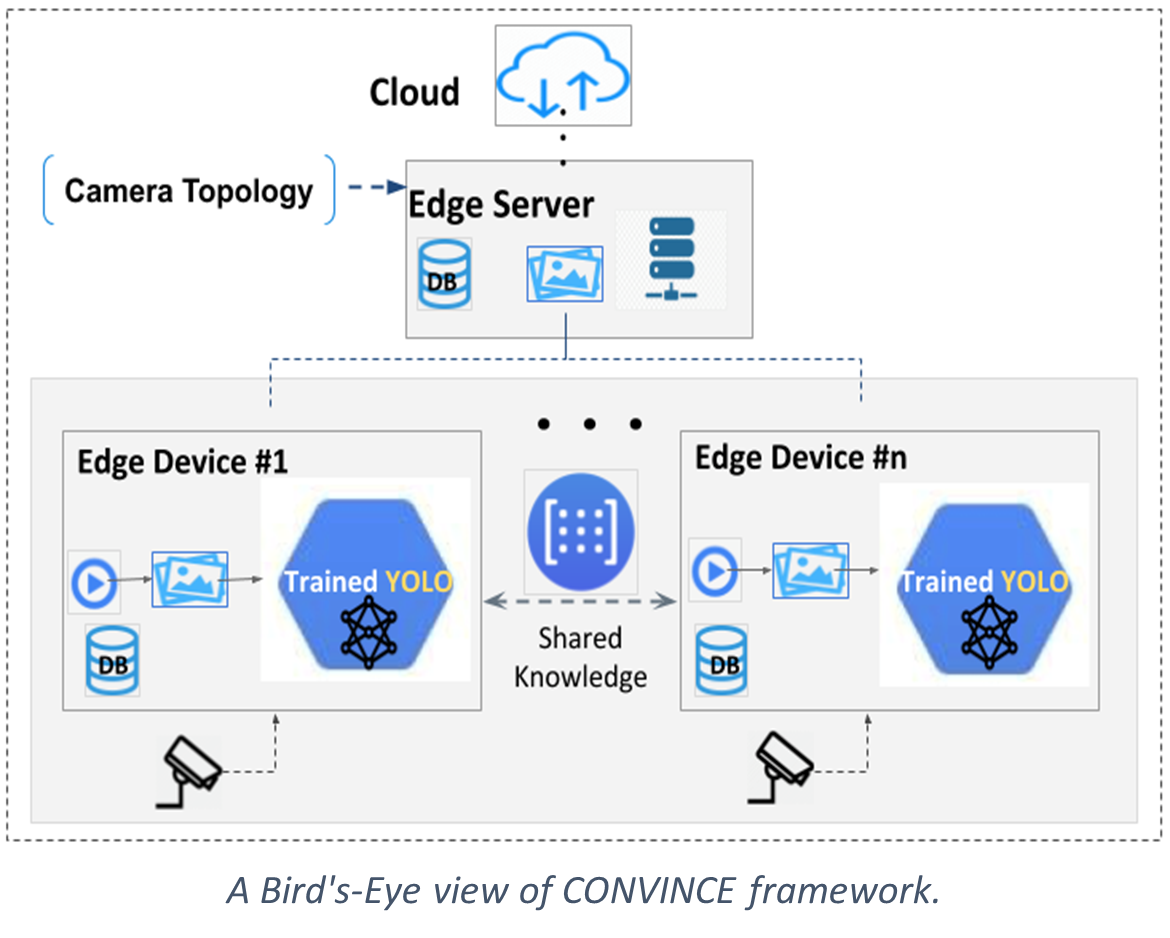
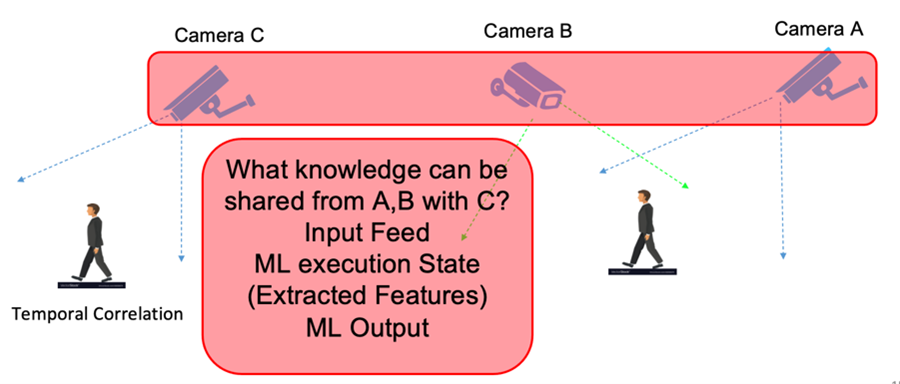
Motivated by the aforementioned hurdles, we believe that there is a need for a new paradigm that can benefit the current systems by lowering energy consumption, bandwidth overheads, and latency, as well as providing higher accuracy and ensuring better privacy by pushing the video analytics at the edge. We are convinced that by looking at a network of cameras as a collective entity that leverages i) spatio-temporal collations among cameras in one hand, and ii) knowledge sharing (e.g., sharing input, intermediate state, or output of the DNN models) among relevant cameras in the other, we can utilize the aforementioned benefits in our systems. Prior works fail in addressing the challenge of large-scale camera deployments where the compute cost grows exponentially by the increase in the number of deployed cameras. Most of the recent works only focus on a single camera (not a collection of cameras) to perform the given vision task. Recent systems have improved analytics of live videos by using frame sampling and filtering to discard frames [2]–[4]. However, the focus of these works are on optimizing the analytics overhead for individual video feeds. To demonstrate the new opportunities and challenges in our vision, we have designed a centralized collaborative cross-camera video analytics system at the edge hereafter CONVINCE that leverages spatio-temporal correlations by eliminating redundant frames in order to reduce the bandwidth and processing cost, as well as leveraging knowledge sharing across cameras to improve the vision model accuracy. Applications that could benefit from such a system include, but not limited to, public and pedestrian safety, retail stores (e.g., Amazon Go) and vehicle tracking.
Publications
- Hannaneh B. Pasandi and Tamer Nadeem, "CONVINCE: Collaborative Cross-Camera Video Analytics at the Edge," 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 2020
- Hannaneh B. Pasandi and Tamer Nadeem, "Collaborative Intelligent Cross-Camera Video Analytics at Edge: Opportunities and Challenges", The International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things (AIChallengeIoT 2019) in conjunction with ACM SenSys 2019, New York, NY, USA, November 10, 2019.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.